The challenge is closed. You can browse the results, but you cannot make new submissions.
A suite of AI metrics that can be used to measure and track the performance of the task-specific models.
Join a community shaping the future of multilingual communication. With Speechm, you can test cutting-edge AI models, contribute to innovation through leaderboards, and help refine solutions like real-time translation and speech recognition — ensuring seamless, global collaboration for everyone.
Join us
Unlock the Future of Speech Technology
Explore our innovative AI solutions that empower seamless communication and drive progress in the field of speech technology.
60
models
4
test sets
10
metrics
Key Tasks in NLP and Speech Technology
Explore the core functions that enhance communication through language understanding, translation, and speech recognition.
-
Offline (OFFLINE)
Offline Speech Translation Task at IWSLT is the one with the longest-standing tradition at the conference. The task provides a stable evaluation framework for tracking technological advancements in Spoken Language Translation (SLT), with a focus on unconstrained SLT—free from the temporal and structural constraints imposed by tasks such as simultaneous translation or subtitling. Such an unconstrained condition offers a good estimate to the current upper limit of our speech technologies, making this offline task the foundation of other shared tasks.
-
Model Compression (MODELCOMPRESSION)
Text and speech foundation models have revolutionized many natural language processing tasks, including speech-to-text trnslation. However, their large size and high computational demands pose significant challenges when deploying these models in real-world scenarios, particularly in resource-constrained environments such as mobile devices, embedded systems, and edge computing. Reducing the size of large, general-purpose models while preserving or even improving their performance in specific tasks or language settings is essential for making them more efficient, accessible, and sustainable. This task focuses on evaluating participants’ ability to apply model compression techniques to a large multilingual speech-to-text model, balancing the need for accessibility and deployment feasibility with the requirement for good performance in English-German and English-Chinese speech translation.
-
Instruction-Following Short (IFSHORT)
Large language models (LLMs) have demonstrated the capability of performing several NLP tasks without the need for building dedicated models, offering a single solution for many applications. While solely processing text in their initial stage, LLMs are now being enhanced by integrating other modalities, like vision and audio. In this scenario, the emerging paradigm of creating a unique architecture from speech foundation models (SFMs) and LLMs is gaining traction to combine the best of both worlds: the ability to process spoken language inputs with the always-evolving language knowledge of the LLMs. For this reason, this year, we introduce the first shared task at IWSLT aimed at testing general and universal models for the speech modality.
-
Instruction-Following Long (IFLONG)
Large language models (LLMs) have demonstrated the capability of performing several NLP tasks without the need for building dedicated models, offering a single solution for many applications. While solely processing text in their initial stage, LLMs are now being enhanced by integrating other modalities, like vision and audio. In this scenario, the emerging paradigm of creating a unique architecture from speech foundation models (SFMs) and LLMs is gaining traction to combine the best of both worlds: the ability to process spoken language inputs with the always-evolving language knowledge of the LLMs. For this reason, this year, we introduce the first shared task at IWSLT aimed at testing general and universal models for the speech modality.
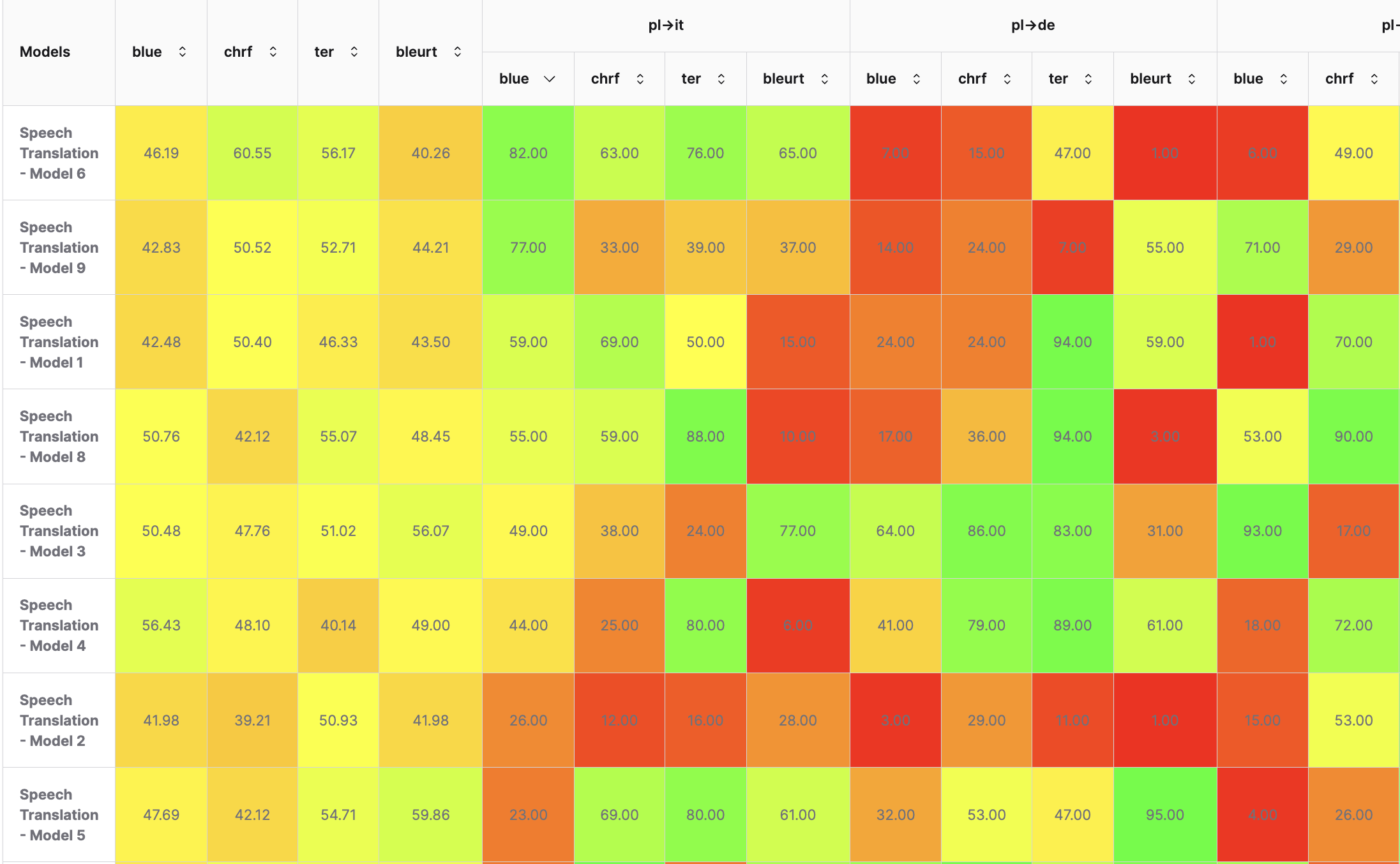
Discover the Best Model Tailored to Your Needs
Our leaderboards cover a wide range of tasks, from speech translation to text generation and beyond, offering detailed comparisons of models tested across various datasets and language pairs. With rankings based on performance metrics like BLEU, CHRF, TER, and more, you can easily find the model that meets your specific requirements.
Explore, compare, and select the best solution for your task.